18 Mayıs 2014 Pazar
Yeni İçerik Fikirleri
Uzun bir süredir yeni yazı yazmıyordum. Yeniden yazmaya başladım. Bundan sonra SPSS ile ilgili birkaç yazı ekledikten sonra veri madenciliği, R , SQL, Orange, Weka gibi konular üzerine yazmayı düşünüyorum. Eğer varsa sizlerin önerilerini de duymayı çok isterim. (Yorumlarla yada doğrudan bana mail atarak önerilerinizi bana ulaştırabilirsiniz.)
Virgülle Ayrılmış Veri Setini(CSV) SPSS ile Açma
Virgülle ayrılmış veri(Comma Seperated Values - CSV) formatı veri analizi çalışmalarında en yaygın olarak kullanılan dosya tipidir. Bu kadar yaygın olmasının sebebi neredeyse mevcut bütün veri analizi programları tarafından desteklenmesidir. Ayrıca farklı programlar arasında da kolay veri aktarımını sağlar. Örneğin veri tabanlarından dışarı veri aktarma aşamasında(exporting) yada açık kaynak kodlu R, Weka, Orange gibi programlardan SPSS, Excel gibi daha yaygın programlara veri aktarımında kullanılabilir.. Bu bölümde bu dosya tipinin SPSS'e nasıl aktarılacağına bakacağız. Örnek dosyayı buradan indirebilirsiniz.

Bu tip dosya tipleri "Virgülle Ayrılmış Veri" olarak çağrılsa da aslında genellikle değişkenler noktalı virgülle(;) ile ayrılır. Bunun sebebi ondalıklı sayıların virgüllü kısmının programlar tarafından ayrı bir değişken olarak algılanmasını engellemektir.
SPSS' de bu tip dosyaları açarken "File > Open > Data" bölümünden yada doğrudan ilgili dosyayı SPSS'in data editörünün üstüne sürükleyerek SPSS'in text okuma sihirbazını çalıştırabilirsiniz.

Bundan sonra açılan pencerede SPSS bilgisayarınızdan ilgili dosyayı bulmanız gerekiyor. Aşağıdaki bölümde gösterilen dosya tiplerini değiştirmeyi unutmayın. Aksi takdirde SPSS sadece kendi dosyalarını(.sav uzantılı)
gösterecektir.



Bu pencerenin ilk kısmında verilerin belirli bir ayraçlamı yoksa bir hizaya göre mi ayrıldığını soruyor. Bu veri seti bir ayraçla(noktalı virgül) ayrıldığı için "Delimited" seçeneği seçilir. İkinci bölümde ise veri setinin en üst satırında veri isimlerinin olup olmadığını soruyor. Bu veri setinde veri isimleri en üst satırda olduğu için "Yes" i seçip ilerleyebilirsiniz.

Bir önceki pencerede veri isimleri en üst satırda olduğu için verilerin başladığı satır numarası kendiliğinden 2 olarak ayarlanıyor. Bu pencerede aynı zamanda örneklemede yapılabilir. Verilerin tamamını, ilk x tane veriyi yada rastgele olarak belirli bir yüzdesini seçebilirsiniz.

Bu bölümde ise verilerin ne tür bir ayraç ile ayrıldığı seçilir. Burada "Semicolon(noktalı virgül)" seçeneğini işaretlendiğinde verilerin bir düzene girdiği görülebilir.



17 Kasım 2012 Cumartesi
SPSS:Lİneer Regresyon

Y : Bağımlı değişken
X: Bağımsız değişken
B: Katsayılar
E: Artıklar
olmak üzere Y=B0+B1+B2X2+…+BkXk+ei şeklinde bir denklem elde edilir. Böylece "şu "X" verisi için "Y" değeri bu olacaktır." şeklinde tahminler yapılabilir. ( Örnekte incelenecek veri setini buradan indirebilirsiniz... )


SPSS' de " Analyze > Regression > Linear "





15 Kasım 2012 Perşembe
SPSS:Correlation


Bivariate: İki değişken arasındaki korelasyon katsayısını bulmak için kullanılır.
Partial: İncelenen iki değişkenle ilişkisi olduğu düşünülen bir yada birden fazla değişkenin göz önünde bulundurularak iligili iki değişkenin arasındaki korelasyon katsayısını hesaplamak için kullanılır.
(Örnekte incelenecek veri setini buradan indirebilirsiniz.)

Bu veris setinde "y" değişkeni bağımlı değişken ve x1, x2, x3 değişkenleri ise bağımsız değişkenlerdir. Bunlar kişilere ait vucut ağırlıkları(y) ve bu kişilere ait farklı vucut ölçüleridir(x1,x2,x3). İlk olarak bağımsız değişkenler arasındaki korelasyon katsayılarını inceleyelim.
SPSS' de " Analyze > Correlation > Bivariate "

Bu seçimler yapıldıktan sonra sonuçlar aşağıdakilere benzer şekilde olacaktır.

Şimdi "Body Fat" değişkenini göz önünde bulundurarak aynı değişkenler arasındaki korelasyonu(kısmi korelasyon) hesaplayalım.
SPSS' de " Analyze > Correlation > Partial "


13 Kasım 2012 Salı
SPSS:MANOVA


SPSS' de " Analyze > General Linear Model > Multivariate "






12 Kasım 2012 Pazartesi
SPSS:Univariate ANOVA

Univariate ANOVA, iki yada ikiden daha fazla faktöre ait değişkenlerin ortalamalarını karşılaştırmak için kullanıllır. One-Way ANOVA' dan farkı iki yada ikiden daha fazla faktörün olmasıdır. ANOVA testiyle hangi faktörün bağımlı değişken üzerinde anlamlı bir etkisi olup olmadığı tespit edilir. Post Hoc testleriyle ise eğer faktör düzeyleri arasında bir farklılık var ise bu faklılığın hangi düzeyler arasında olduğu bulunur. Varsamyımlar One-Way ANOVA ile aynıdır. Nomallik ve varyansların homojenliği. (Örnekte incelencek veri setini buradan indirebilirsiniz.)

H0: %95 güvenle, faktör düzeylerinin ortalamaları arasında istatistiksel olarak anlamlı bir farklılk yoktur.
H1: %95 güvenle, faktör düzeylerinin ortalamaları arasında istatistiksel olarak anlamlı bir farklılk vardır
SPSS' de " Analyze > General Linear Models > Univariate " (Resimleri büyütmek için üzerine tıklayın...)



"Tukey" testi tercih edilir. Varyansların homojen olmaması durumunda ise genellikle " Tamhane' s T2" testi tercih edilir.





6 Kasım 2012 Salı
SPSS:One Way ANOVA(Tek Yönlü Varyans Analizi)


Varyansların homojenliği testi için hipotezler;
H0: %95 güvenle grup varyanslar homojendir.
H1: %95 güvenle grup varyansları homojen değildir.
Tek yönlü varyans analizi için hipotezler;
H0: %95 güvenle, grupların ortalamaları arasında istatistiksel olarak anlamlı bir farklılık yoktur.
H1:%95 güvenle, grupların ortalamaları arasında istatistiksel olarak anlamlı bir farklılık vardır.
SPSS' de "Analyze > Compare Means > One-Way ANOVA"



Bu seçimler yapıldıtan sonra sonuçlar aşağıdaki gibi olacaktır.

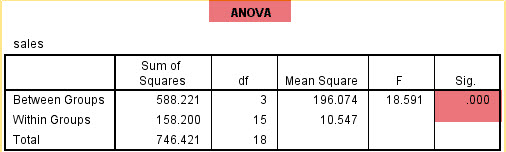
Hangi grupların ortalamaları arasında farklılıklar olduğunu görmek için bir sonraki tablo incelenir. (Tabloyu büyütmek için üzerine tıklayınız.)


Kaydol:
Kayıtlar (Atom)